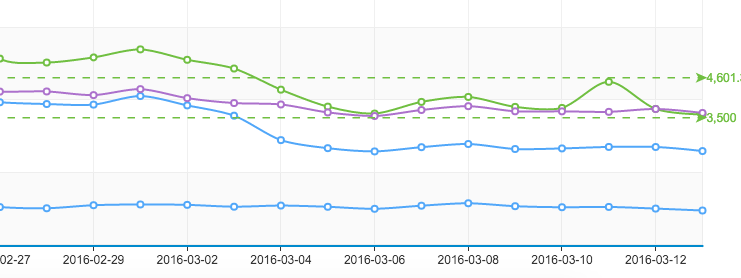
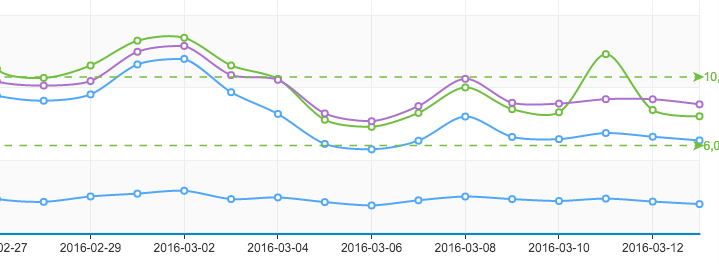
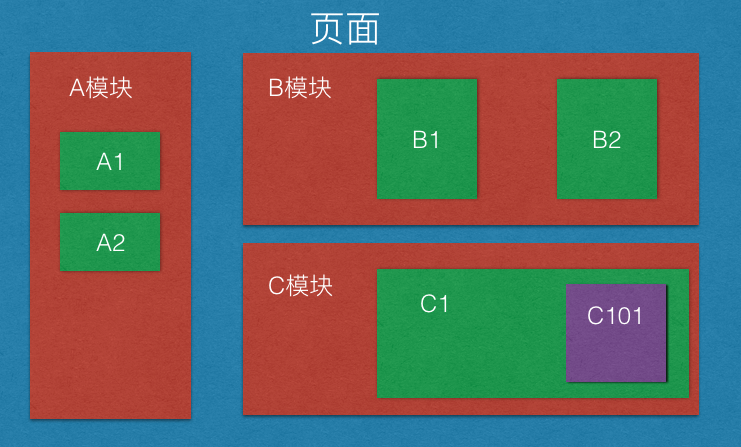
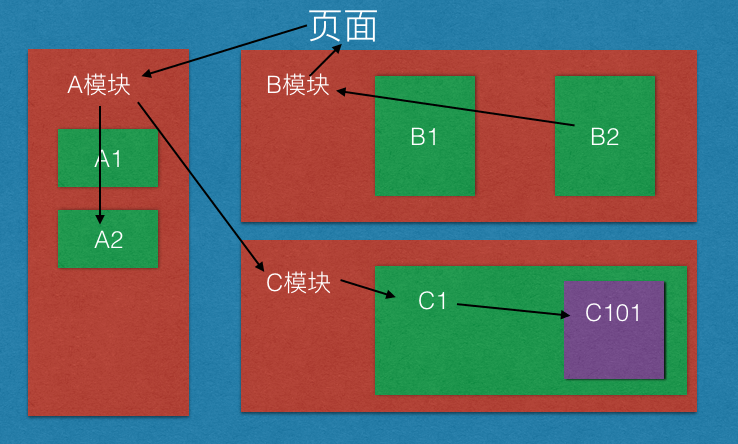
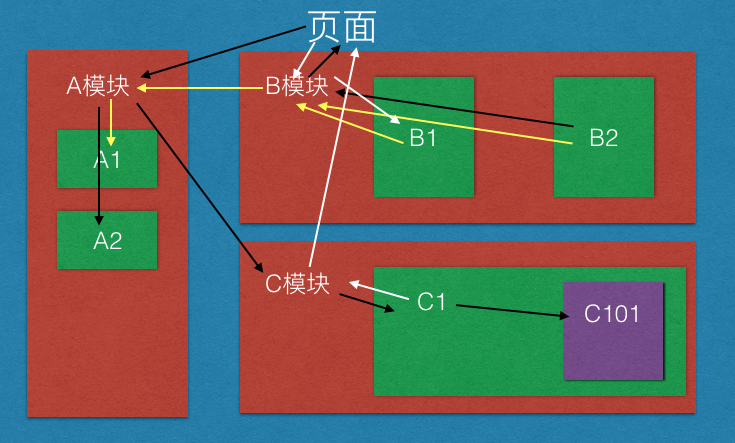
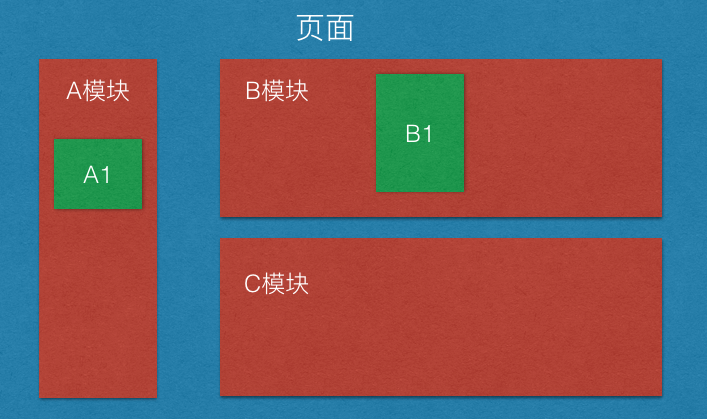
之前谈到过很多次数据驱动的理解,这次通过实际项目检验了一下自己的想法。
相关文件
项目详设
详设的重要性
对于复杂一点的项目,做一个详细设计非常重要。有人会疑惑,前端还需要详设吗?
根据我的经验,详设非常重要,非常体现能力。
对于一个新人,详设能够给开发做一些提前准备。
对于一个老手,详设可以提前预见一些隐藏的坑。
对于一个高手,详设需要达到随便给一个有点经验的人,都能直接写代码。
在某种程度上,开发者详设在整个开发周期中占得比重越大,能力就越强。
新人可能只占5%,高手肯能占到50%以上(架构完全想清楚了,然后剩下用代码去实践设计)。
react详设的步骤
- 吃透业务,这个不管用什么选型都很重要
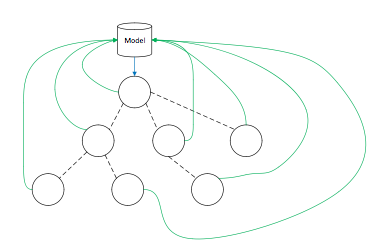
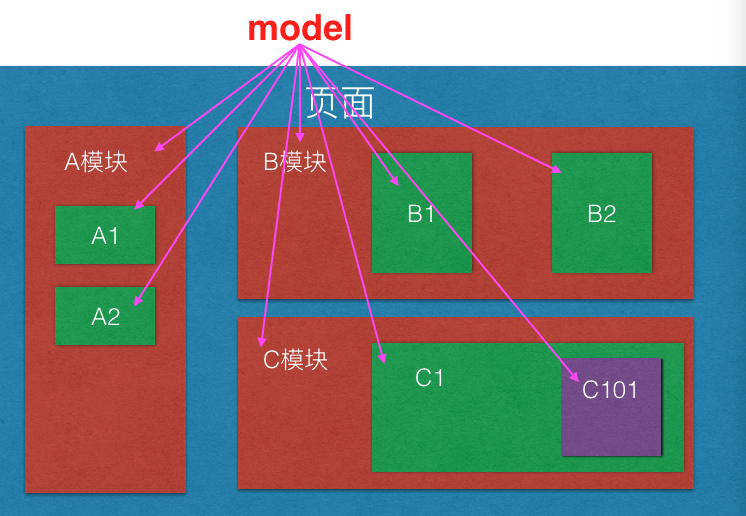
- 顶层数据结构,model必须梳理清晰,model需要能够完整的覆盖业务
- 业务React Component中每一个的props,state布局,props,state中每一项的用处,计算方式,与顶层数据结构的映射函数
- 业务React Component中每一个的Action对于的model改变
- model上面添加和后端的关联
基本上上面梳理清楚了,后面就可以直接写代码了。
道和术
网上看到很多讲解redux+react的实践思路,设计模型。感觉都是实践方式上面的讲解。
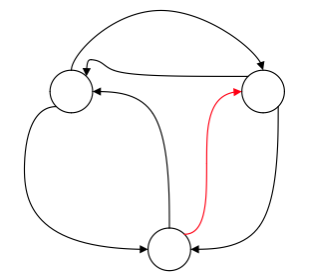
比较经典的一张图: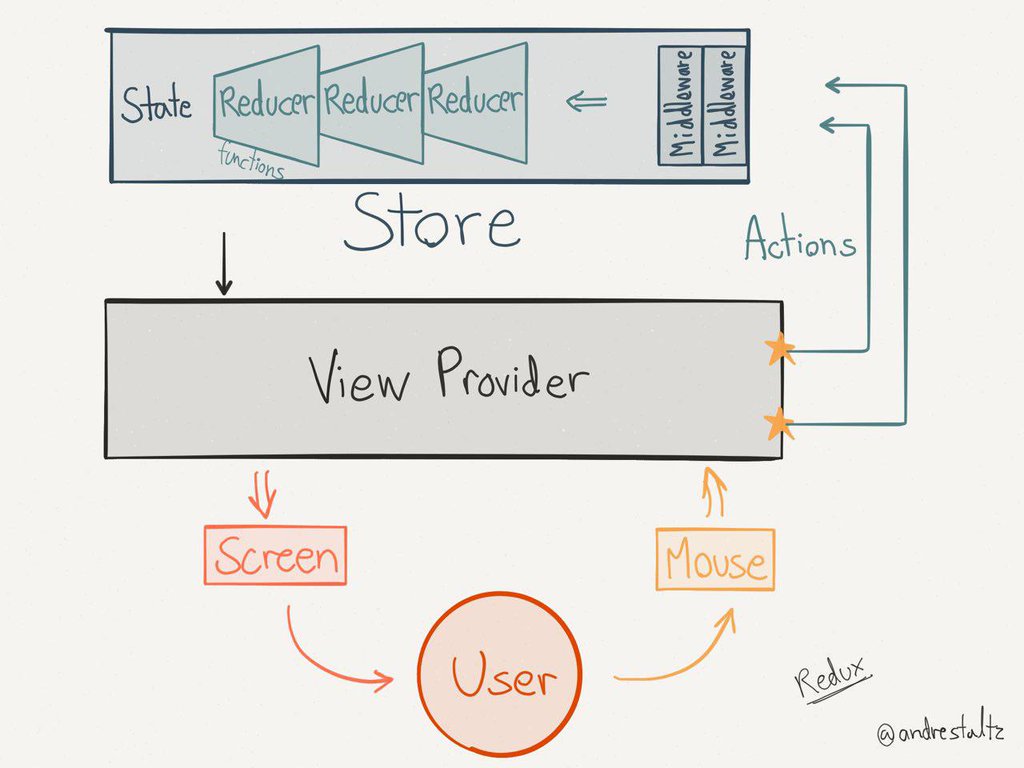
今天我这边想换一种思路去解释他。
数据驱动+react实践的一个前提
相信react的性能!
相信react的性能!
相信react的性能!
快照概念
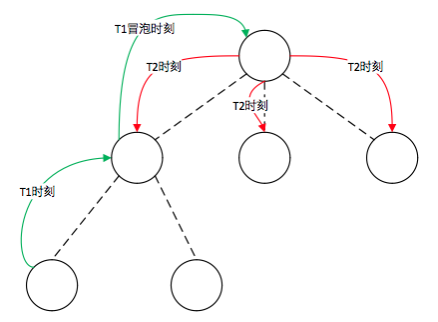
model能力超级强大,请记住,每个model都必须能够对应一种页面状态(能够像恢复快照一样)。model和页面状态存在一种一一对应的关系。
如下图:
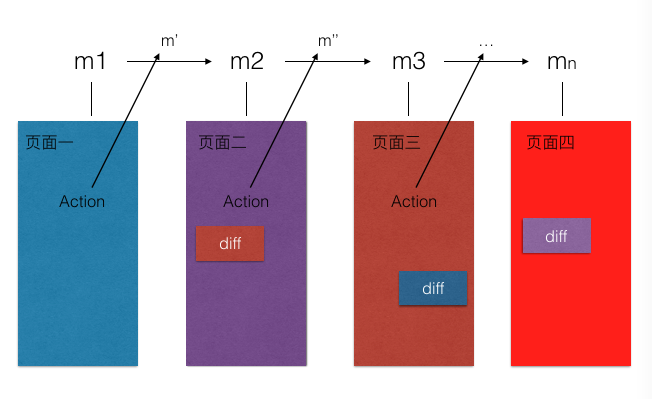
每一个M都和下面的页面对应,用M1可以render出第一个页面,M2可以render第二个页面。
当用户有交互行为时,通过action改变M1到M2,这时大家注意了
慢动作:
用户对M1的页面一做了一个操作(action)让M1产生了改变M',这时M1变成了M2,对应的页面也由页面一刷新成了M2对应的页面二。同理,M2通过交互变成了M3,页面也会刷新成M3对应的页面三。
注意我强调了刷新两个字。
核心就是页面的行为使得数据改变,数据渲染出数据改变后相应的页面。
这个就是我所理解的数据驱动。
为了达到上面目的,其实我们有意忽略了性能问题。就是用户每次操作都会重新渲染数据,生成对应的新页面。
那么性能问题如何解决,这时react就出场了,性能上,我们需要借助react的虚拟dom,去比较每一次页面修改的最小diff,然后重新渲染diff部分。所以我上面提到,你需要相信react的性能。
说实话,如果没有这种最小diff的处理能力,这种完全的数据驱动性能问题非常大。
从上面看,代码其实可以分为两大部分:
- render: 根据model写渲染逻辑,这部分就交给react,大家仔细看看react的生命周期,都是围绕render的
- change model: 根据用户的action,修改model的数据,这部分交给redux的模式
数据驱动副产物
单元测试
某种程度上,前端是非常难去写单侧的,因为涉及到dom,哪怕是时间允许,单侧的使用度也不是很高。
对于数据驱动这种模式,至少从数据层,可以规避dom,做一层数据变化的效验(这个和写服务端单侧差不多)。然后有精力和时间,可以加一层model-to-dom逻辑的测试。
用户行为回放
回答上面那个图片,通过model可以记录一个页面的快照,那么如果对于单个用户,单个终端,按照时间轴记录一连串的model,我们就可以回放用户的操作行为。
以及利用大数据去批量分析用户行为数据。
数据驱动的思考
这种模式某种程度上,是为了提高开发效率,减少页面的复杂度(参考《前端数据驱动的价值》),减少开发的复杂度。
想想5-6年前,还是多页面时代,每个模块都是一个页面,数据都由后端去套模板。然后用户每个操作基本上都会触发一些刷新。数据驱动和有点类似,只是借用react在单页面上实现了。前端也承担了更多的数据处理工作。